
Uber Freight dévoile le premier programme de partenaires de conception de l’industrie lors du salon Deliver
septembre 11, 2024 / US

Par : Mudit Gupta, Sr. Data Scientist ; Mohit Gulla, Applied Scientist ; et Angelo Mancini, Applied Science Manager
Dans le secteur de la logistique, il est essentiel de comprendre quand un chargement est en retard pour atténuer les conséquences d’un mauvais service. En cas de préavis, Uber Freight peut travailler avec le transporteur et l’expéditeur pour atténuer l’impact d’une arrivée tardive. Cependant, les arrivées tardives sont souvent détectées trop tard pour que des ajustements puissent être effectués, ou ne sont pas détectées avant que l’heure du rendez-vous ne soit passée.
Chez Uber Freight, notre système de suivi est conçu pour fournir un service de la plus haute qualité aux expéditeurs. En combinant nos données de suivi internes avec notre compréhension approfondie de la logistique et notre expertise en matière d’apprentissage automatique, nous avons développé un système qui affine en permanence nos données sur les emplacements des installations et s’appuie sur ces données pour présenter à notre équipe opérationnelle des prévisions en temps réel sur les arrivées tardives.
Pour prédire si un transporteur arrivera ou non à l’heure à une installation, il faut trois éléments clés : (1) la localisation de l’installation, (2) les géofences autour de l’installation que nous pouvons utiliser pour détecter quand un transporteur est arrivé ou parti d’une installation, et (3) un modèle qui peut prédire en temps réel l’arrivée tardive en fonction de la localisation d’un transporteur et de la localisation de l’installation. Comme nous le verrons dans l’exemple suivant, si l’un de ces composants tombe en panne, c’est tout le système qui s’écroule.
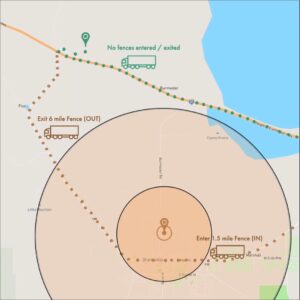
Figure 1 : Deux camions se dirigeant vers la même installation (épingle verte) génèrent différents types d’erreurs de suivi lorsque le système a une localisation inexacte de l’installation (le cercle marron, avec une géofence d’arrivée de 1,5 mile et une géofence de départ de 6 mile).
Dans le cas du camion vert, aucune géofence n’est déclenchée, ce qui signifie que, d’après le système, le transporteur n’est jamais arrivé à l’installation (même s’il est peut-être arrivé à l’heure). Dans le cas du camion marron, les deux géofences sont déclenchées <pendant que le transporteur est en transit vers l’installation réelle, ce qui signifie que le système enregistrera à tort le transporteur comme étant arrivé à l’installation à la mauvaise heure, enregistrera le transporteur comme ayant passé très peu de temps dans l’installation (puisque le transporteur ne fait que passer, ce qui est connu sous le nom de « défaut de séjour »), et enregistrera le transporteur comme ayant quitté l’installation à l’heure erronée. Pour les deux camions, toute prévision d’arrivée tardive effectuée pendant qu’ils sont en transit ne serait pas fiable car le modèle ferait des prévisions en utilisant les données de l’enquête. <localisation incorrecte de l’installation.
Cet exemple motive l’approche que nous avons adoptée pour construire notre système de suivi : affiner les principes fondamentaux (localisation et géofences) afin de construire un modèle d’arrivée tardive de haute qualité. Tout au long du projet, nous avons exploité la grande quantité de données historiques de charge et de suivi dont nous disposions.
Obtenir des données de localisation pour les installations d’expédition semble simple, n’est-ce pas ? Après tout, ce sont les camions qui se déplacent, pas les installations. Malheureusement, ce n’est pas si simple. Lorsque nous avons examiné les données relatives à la localisation de nos installations au début de notre projet, nous avons constaté que les localisations que nous obtenions des sociétés de navigation GPS existantes étaient souvent incorrectes. Pour un échantillon de 500 des plus grandes installations de notre réseau, environ 40 % d’entre elles avaient une localisation GPS incorrecte, y compris 10 % des cas où la localisation de l’installation était erronée d’au moins 0,3 miles (très probablement cartographiée au centre du code postal de l’installation). Une erreur de 0,3 miles peut sembler insignifiante, mais pour ces installations, nos données indiquent qu’environ 24 % des chargements avaient des heures d’arrivée et de départ incorrectes enregistrées par le système.
Nous nous sommes tournés vers nos données internes de suivi GPS, que nous collectons par le biais de l’application mobile de transport Uber Freight pour des milliers d’expéditions quotidiennes. La figure 2 ci-dessous illustre notre approche.
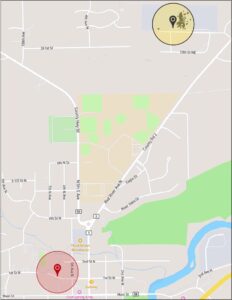
Figure 2 : La localisation de l’installation dans le système (cercle rouge) est incorrecte ; la localisation correcte peut être identifiée en analysant l’emplacement des pings GPS des transporteurs visitant l’installation.
Cet exemple montre clairement que l’emplacement de l’installation du système est incorrect et que l’installation est en fait située près de la grappe de pings en haut à droite. Cependant, effectuer cette analyse manuellement pour chaque établissement n’est tout simplement pas faisable compte tenu de l’ampleur de notre réseau. Au lieu de cela, nous avons construit un modèle d’apprentissage automatique pour analyser nos données GPS historiques et identifier des groupes de pings associés à des installations. Pour garantir la précision de l’algorithme, nous avons ajouté des vérifications de bon sens, comme la distinction entre les signaux reçus des transporteurs qui se déplacent et ceux qui sont à l’arrêt, l’élimination des clusters associés aux aires de repos, aux arrêts de ravitaillement et à d’autres lieux parasites, et l’exclusion des signaux GPS des répartiteurs qui ne sont pas réellement en transit.
Après avoir nettoyé nos données historiques sur la localisation des installations, nous exécutons régulièrement l’algorithme Pinpoint pour nous assurer que la localisation de nos installations est toujours à jour et que nous identifions le plus rapidement possible les emplacements des nouvelles installations qui rejoignent notre réseau.
Comme nous l’avons vu dans le premier exemple, le système de suivi automatisé d’Uber Freight (et de nombreux systèmes de suivi dans le secteur du fret) utilise des géofences pour déterminer l’heure d’arrivée et de départ d’un transporteur dans une installation. Plusieurs problèmes se posent lorsqu’on essaie de tracer de « bonnes » géofences :
Pour relever ces défis, nous nous sommes à nouveau tournés vers nos données GPS internes de haute qualité. Dans le cadre du projet Lasso, nous avons mis au point un algorithme qui analyse des centaines de milliers de signaux GPS afin de créer automatiquement une géofence sur mesure pour nos installations. Alors que la géofence standard est un cercle d’un rayon de 1,5 mile, nous avons été en mesure de produire des géofences avec des rayons aussi petits que 0,1-0,3 miles autour de l’installation ou du quai de chargement à l’intérieur de l’installation. Les figures 3 et 4 ci-dessous montrent comment nous avons converti les données GPS en gènes pour une variété d’installations.
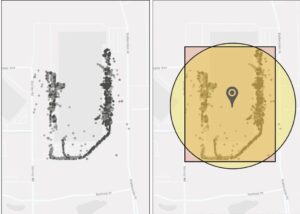
Figure 3 : (à gauche) pings GPS bruts pour les transporteurs visitant l’installation ; (à droite) localisation de l’installation et géofence automatiquement dérivée des pings GPS.
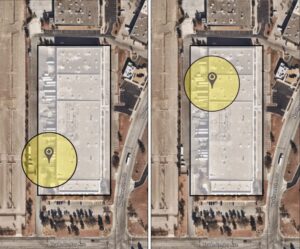
Figure 4 : Deux lieux et géofences différents identifiés dans la même installation, mais reliés à des expéditeurs différents.
Le projet Lasso a permis aux expéditeurs et aux transporteurs de gagner du temps en réduisant les litiges concernant les heures d’arrivée et de départ. Nous avons également constaté une réduction (relative) de 60 % de la fraction des chargements présentant un type de comportement manifestement incorrect, c’est-à-dire des défauts de séjour dans lesquels un transporteur semble avoir passé < 15 minutes entre l’arrivée et le départ, et des défauts de transit dans lesquels le transporteur semble avoir roulé à une vitesse supérieure à 80 miles par heure en moyenne entre deux arrêts. Ces améliorations nous donnent confiance dans les heures d’arrivée et de départ enregistrées dans notre système.
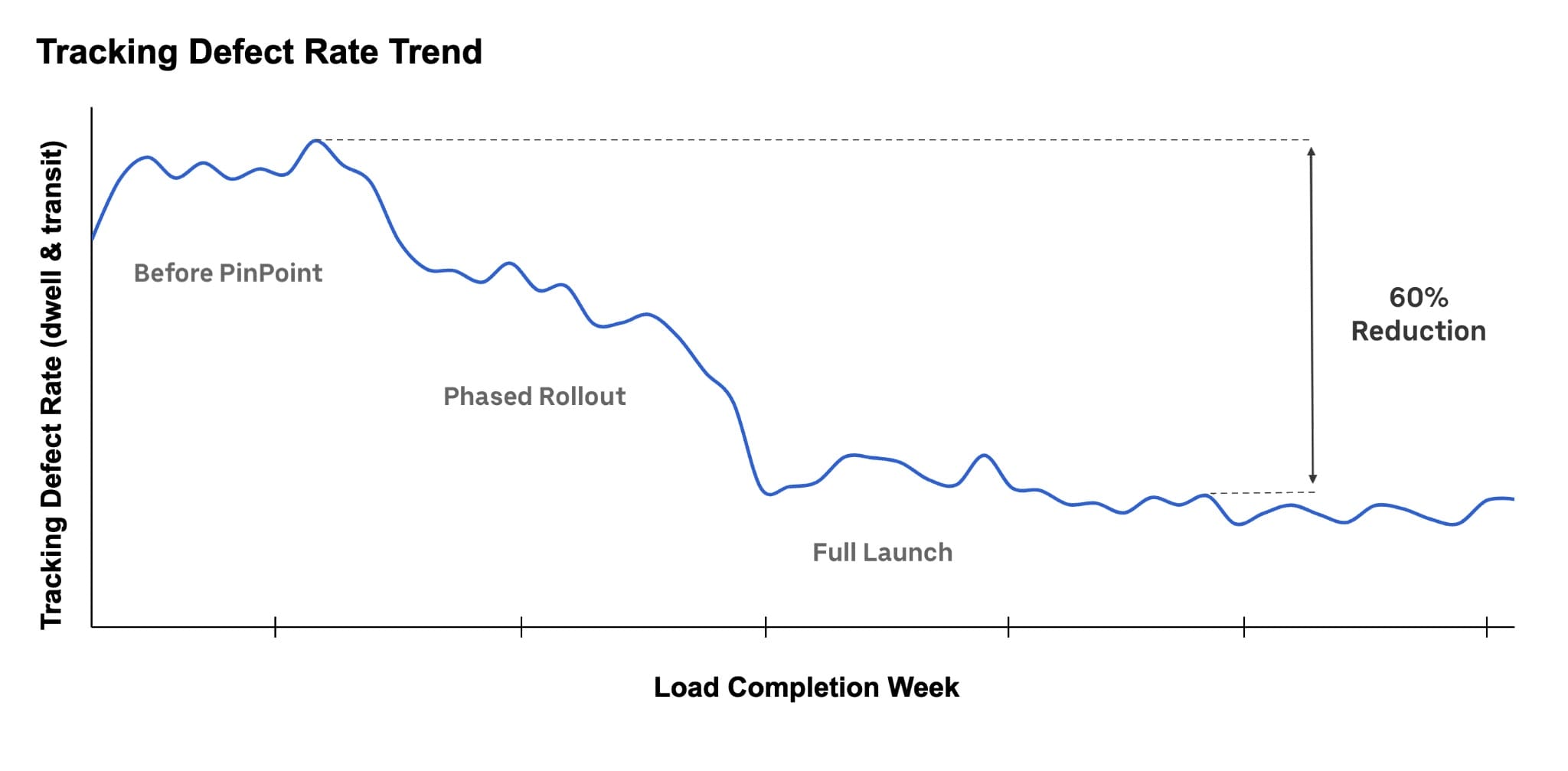
Figure 5 : Le projet Lasso a entraîné une réduction soutenue de 60 % (en termes relatifs) des taux de défauts de suivi après son lancement complet.
Après avoir consolidé les fondations de notre système en corrigeant l’emplacement des installations et en établissant des géofences sur mesure, nous étions prêts à relever notre premier défi : fournir des prévisions d’arrivée tardive en temps réel et de haute qualité à grande échelle. Nous avons suivi un processus en quatre étapes :
Grâce à ces prévisions, notre équipe opérationnelle peut concentrer son attention sur les chargements susceptibles d’arriver en retard et prendre des mesures d’atténuation telles que contacter le transporteur pour s’assurer de sa présence, alerter l’expéditeur afin qu’il puisse prolonger ou reprogrammer le rendez-vous, ou réaffecter le chargement à un autre transporteur (ce que l’on appelle également « rebondir » le chargement). Depuis le lancement du modèle de probabilité d’arrivée tardive (PLA) en production, nous avons constaté une amélioration significative de notre capacité à signaler les chargements tardifs et à détecter les chargements rebondis.
Nous considérons le projet d’apprentissage automatique des retards évoqué ici comme la première étape d’une feuille de route ambitieuse visant à améliorer les résultats en matière de service pour nos chargeurs. Nous travaillons activement sur un modèle d’estimation du temps d’arrivée (ETA) pour accompagner notre modèle PLA. La modélisation de l’heure d’arrivée prévue est omniprésente dans le domaine de la consommation et de la vente au détail (nous avons tous utilisé une application de navigation ou vu les heures d’arrivée prévues pour les livraisons de produits alimentaires), mais la prévision de l’heure d’arrivée prévue pour le fret pose des défis distincts. Par exemple, les trajets de transport de marchandises durent souvent beaucoup plus longtemps que les trajets de livraison de nourriture ou de covoiturage, traversent plusieurs zones géographiques avec des conditions de circulation et météorologiques différentes, et sont influencés à la fois par les réglementations sur les heures de service et par le comportement des transporteurs (par exemple, s’arrêter pour dormir, faire le plein de carburant, etc.)
Avec les modèles PLA et ETA en place, nous développerons des flux de travail automatisés « auto-réparateurs » afin d’améliorer encore le service pour nos expéditeurs. Par exemple, nous pouvons utiliser le modèle PLA pour signaler les chargements qui risquent d’arriver en retard à l’enlèvement, puis utiliser les modèles ETA et PLA pour identifier les transporteurs proches qui pourraient être en mesure d’enlever le chargement à temps, et enfin demander automatiquement aux transporteurs les plus prometteurs s’ils peuvent intervenir pour éviter un rendez-vous manqué. Nous nous appuyons également sur les bases développées dans le cadre du projet sur les arrivées tardives pour aller au-delà du suivi des chargements pour les expéditeurs. Par exemple, en utilisant les heures d’arrivée et de départ améliorées générées par les projets Pinpoint et Lasso, nous avons produit des estimations beaucoup plus précises du temps d’attente des transporteurs dans les installations (« temps de séjour ») et nous avons combiné ces estimations avec nos données internes d’évaluation des transporteurs pour quantifier l’impact d’installations de chargeurs mal exploitées sur la satisfaction des transporteurs et, en fin de compte, sur les coûts des chargeurs.

