
By: Ran Sun, Sr. Product Manager, Jia Wang, Sr. Machine Learning Engineer, Gowtham Suresh, Sr. Applied Scientist
Problem: How to match shippers’ loads to interested carriers
You might think of Uber Freight’s digital brokerage business as an online dating platform. Just as online dating seeks to match individuals, the brokerage aims to pair shippers’ loads with carriers willing to take them. Specifically, shippers turn to us to reach a carrier base broader than what they have access to. Not only does this maximize their potential to achieve the best possible cost and service outcomes, but also both parties can rely on our expertise and technology in managing the downstream load lifecycle.
To find that one true love load, we could ask the carrier to specify their preferences via search – are you a homebody so you need a recurring route that gets you home, or do you have a wanderlust streak and are willing to drive any route? But people can’t always articulate what they want, nor how much those wants matter.
This nuance was the impetus for launching a recommendations system at Uber Freight. We had been putting the burden on carriers to tell us what they want through search, but searching is tedious, carriers have multiple search intents, and they do not always make their preferences explicit. By enabling an automated discovery process, we can service loads more efficiently and cost-effectively. This builds trust with shippers and increases the amount of freight they tender to our platform—which benefits carriers, giving them more options to find that perfect load. More load volume draws more carriers to the platform, which increases shippers’ ability to efficiently and cost-effectively tender their freight. In sum, a recommendations system is one way to enable the brokerage flywheel, lending a helping hand to shippers and carriers by playing matchmaker.
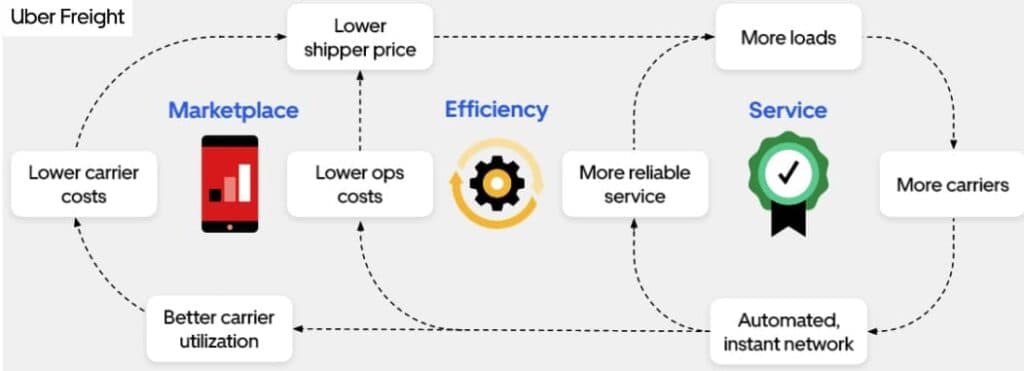
The brokerage flywheel. Recommendations are a component of an automated, instant network and facilitate better carrier utilization.
What is load matching?
Before we delve into our solution, let’s take a moment to define load matching further. In a perfectly optimized network, we’d be able to match the exact right load to the exact right carrier across the nation. However, carrier capabilities and preferences complicate load matching, as do the requirements of the load, such as cargo type, distance to be traveled, and delivery deadline. Our recommendations system judges how strong of a fit may exist between a carrier and a load in order to serve up the best combinations.
What’s the difference between load matching and digital freight matching (DFM)?
Load matching and DFM are closely related concepts. Load matching is the broader term; it refers to the process of connecting shippers with carriers to efficiently utilize transportation capacity. Load matching can be done digitally or non-digitally (e.g. through phone calls or personal relationships). DFM refers specifically to load matching via digital methods. It enables real-time visibility into network needs and carrier capacity, reducing the need for manual intervention.
Solution: A recommendations system
We hypothesized that by replacing the default search page with a page of recommendations, we could move carriers away from a “spearfishing” search model and towards a discovery experience in which they found loads they didn’t even think to look for. Both the design of the user experience and the algorithm itself were critical to the success of this product. In this post, we’ll deep dive into the algorithm.
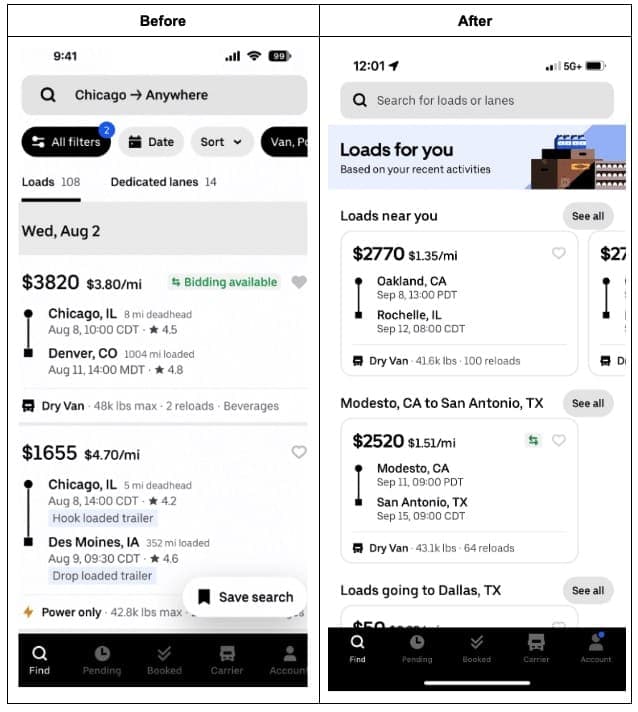
Our recommendations system prioritizes conversion and engagement, similar to those deployed in the e-commerce industry. There are two components: candidate generation and ranker/booster.
Step #1: Candidate generation
We initially wanted to utilize collaborative filtering to generate candidate loads to recommend. Collaborative filtering examines users with similar behavior to infer the preferences of the user in question—similar to how your favorite streaming service leverages user data to recommend content. However, employing this technique using load bookings as the unit of similarity has challenges, since load bookings are exclusive. In the streaming service context, two users can like the same movie. In our context, two users cannot book the same load.
To circumvent this issue, we tried methods such as looking at lane bookings and loads saved as positive signals. (Lane bookings are multiple loads booked on the same geographical route, e.g. San Francisco to Los Angeles.) Both of these do not suffer from exclusivity. However, the viability of these approaches was nixed by the sparseness of the data.
Ultimately, we used several signs of interest from carriers to generate load recommendation candidates:
Saved loads
Clicked on loads
Loads similar to prior bookings
Loads taking freight drivers to their billing address as a proxy for home
Searches executed on our partner vendor sites
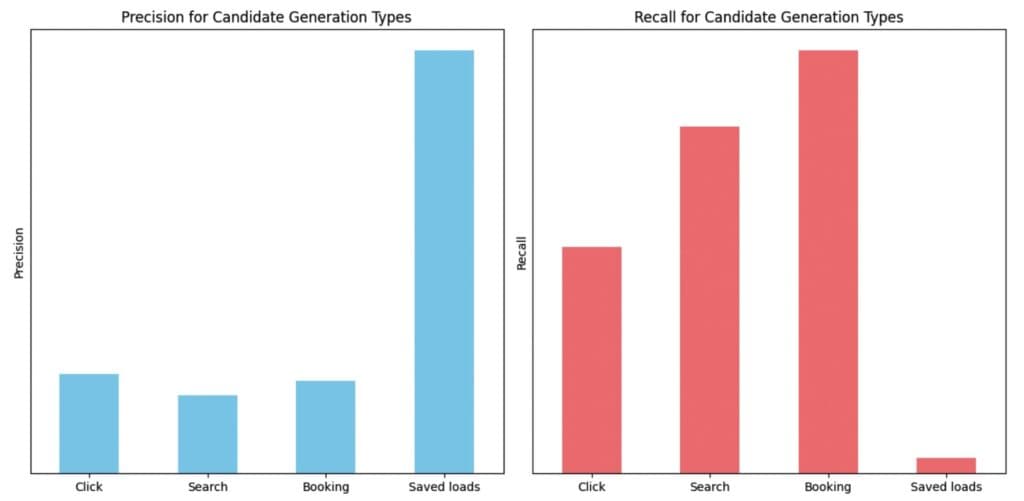
Precision and Recall Comparison for Different Candidate Generation Types
The above chart represents the precision and recall by considering the top 20 ranked loads from each of the candidate generation types. Precision measures how many of the recommendations were actually booked, whereas recall checks what share of bookings were recommended. Typically, we prioritize precision over recall when it comes to recommendations as it is a direct assessment of relevance. Our primary objective is to cultivate trust among carriers by presenting them with the most pertinent loads. Even when such loads are scarce, we lean towards displaying fewer recommendations rather than cluttering the space with less relevant ones. In our offline testing, saved loads consistently yielded the highest precision, making them a robust signal. Clicks and bookings exhibit relatively similar precision and contribute significantly to recall. We intentionally provide an additional boost to candidates from saved loads due to their exceptionally high precision performance.
Step #2: Ranker/Booster
We used the XGBoost algorithm to order the candidate loads generated from the sources mentioned above. The algorithm utilizes load characteristics, carrier personas established in user research and substantiated through data, and the intersection between load characteristics and carrier preferences as features. It then uses the label of whether the load was booked for training and prediction purposes.
Below are the SHAP values of the top 3 features for a sample candidate load. The order of the features illustrates feature importance, the color indicates positive (red) or negative (blue) impact on the outcome variable, and the x-axis indicates the magnitude of impact. Here, the outcome variable is booking probability. Derived_lead_time is the most important feature in determining booking probability. Lead time for this sample indicates low booking probability. Note that feature importance ordering and their magnitude vary by load.
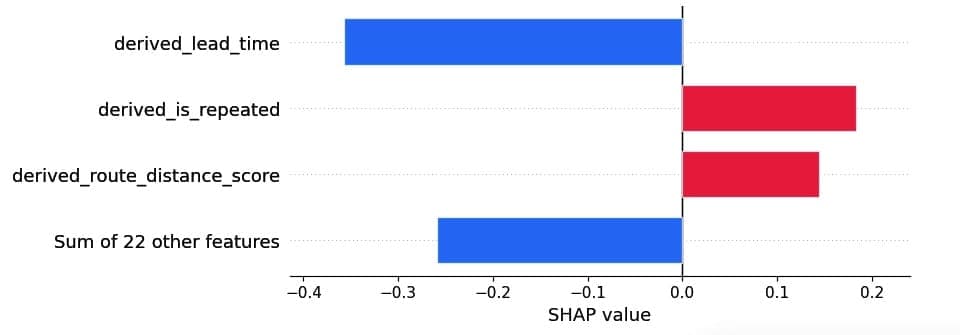
Feature importance using SHAP values for a sample load
We highlight three key features as follows:
Lead time to pickup (“derived_lead_time”): Loads in the freight marketplace can be considered akin to perishable goods, wherein timely booking is crucial. If a load remains unbooked before its scheduled pickup, then we have to reschedule the load, leading to strained relationships with shippers. Incorporating lead time as a feature in the algorithm allows us to capture the dynamic of carriers becoming more inclined to book as the pickup time approaches (because price rises).
Repeat booking (“derived_is_repeated”): A lot of carriers prioritize familiarity. Perhaps familiarity means driving the same route and getting to know the best diner along the drag, or making friends with the warehouse receivers and getting unloaded earlier. To simulate this desire, we developed an exponential kernel function that quantifies the geographical similarity between a given load and the user’s previous bookings.
Distance (“derived_route_distance_score”): Much like how some people enjoy long journeys while others prefer short getaways, carriers also have distance inclinations. We considered a carrier’s previously booked lengths of haul to infer their preference in this respect. A preference score was then assigned to each candidate load based on its length of haul.
Results: Better load matching increases bookings
We tested our new recommendations system with a user-level A/B experiment, to positive results. Lifts occurred throughout the carrier booking funnel, most notably an increase of 12% in bookings for active users and an overall increase of 3% in bookings and 5% in clicks.
What’s next? We’ll investigate several iterations, from improving the experience for select pockets of users to leveraging more data sources in generating load candidates. With these changes, carriers can rely on Uber Freight to help them find the best possible load given their preferences, as efficiently as possible. Now that’s a happy ending.
Interested in learning more about how our team is using AI-driven algorithms to improve logistics for shippers and carriers alike? Read about our probability of late arrival (PLA) model.